Strive for short-lived synchronous communication
When interacting with a service asynchronous communication often is a preferred way. “Enterprise integration patterns” book puts it that way (which also might be a TL;DR; for the rest of the article)
With synchronous communication, the caller must wait for the receiver to finish processing the call before the caller can receive the result and continue. In this way, the caller can only make calls as fast as the receiver can perform them. On the other hand, asynchronous communication allows the sender to batch requests to the receiver at its own pace, and for the receiver to consume the requests at its own different pace. This allows both applications to run at maximum throughput and not waste time waiting on each other (at least until the receiver runs out of messages to process).
However, there might be scenarios when synchronous communication is unavoidable. Let’s have a look at the example.
Communication between services
Let’s imagine we have a system that uploads and processes files. It consists of a legacy module upon which we have no control. This module takes a file from the file system, uploads it to the given endpoint via HTTP and if the upload is successful it uploads a supplementary metadata file.
Since we have no control over the legacy module we have no other option than to stick with synchronous communication. Once the file is uploaded to our system we perform numerous processing activities which consume a considerable amount of time.
We can summarize the current state of affairs with the following diagram.
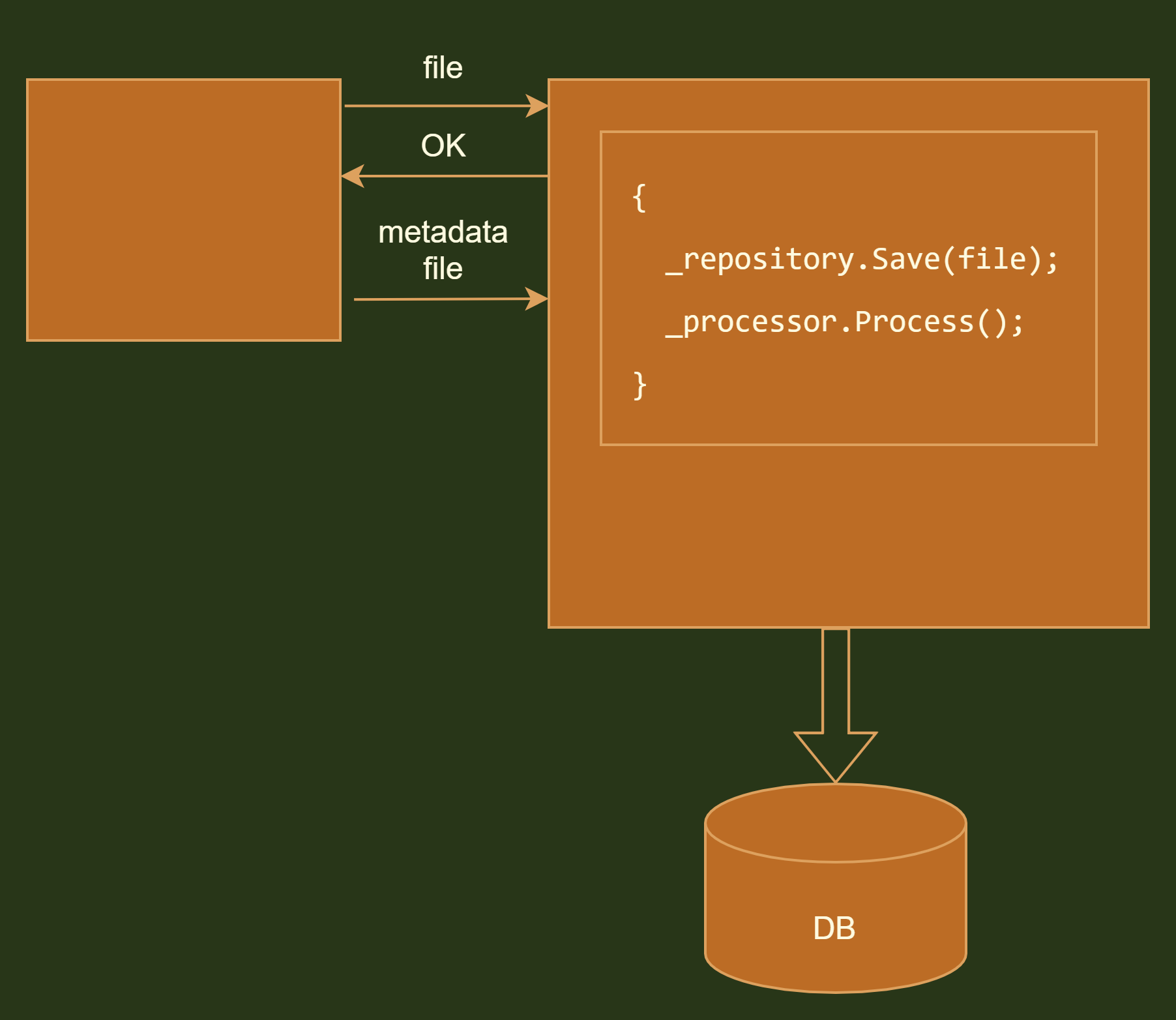
Extracting long running task into separate job
As always, there’s nothing wrong with this design unless you apply some scale to it. But once the requirement to upload a big amount of files arrived it appears evident that the bottleneck is the legacy module waits every time until our code is done saving and processing the file before it can upload the additional file. So in order to fulfill the requirement we need to reduce interaction time. Then you start noticing how wasteful is to wait until processing is done on every HTTP request. The remedy is to return the response early and perform processing in the background.
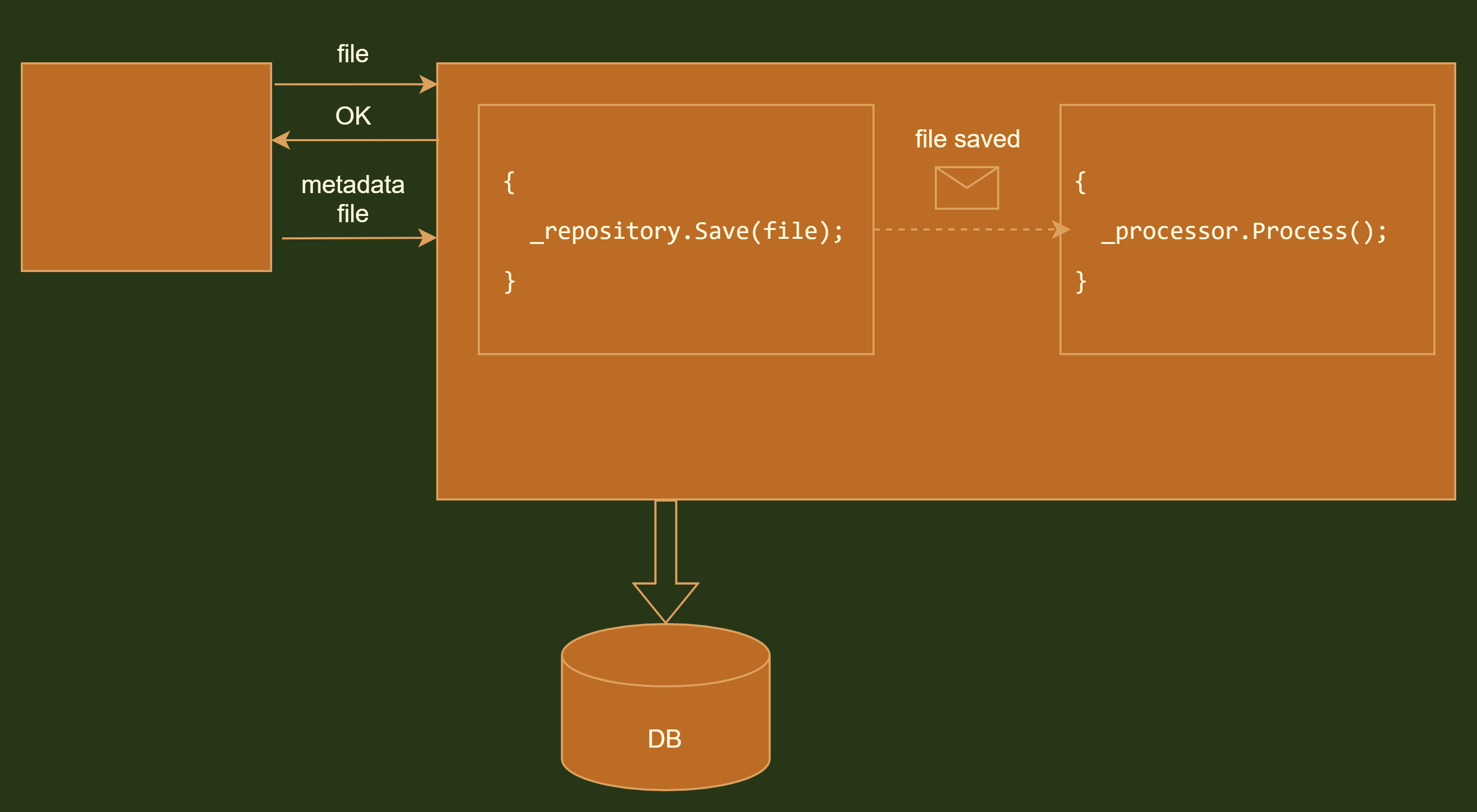
Here asynchronous communication is denoted with the dashed arrow. Once we persist the file we send a message that the file is saved to the processor module. To enable this we might employ AMQP implementation of our taste. Since a message is asynchronous we don’t have to wait for processor response and are able to return the response to our legacy uploader component way earlier.
Notice that both components communicate inside a single process. There’s the reason for this which I’ll cover in the next section.
Scaling solution horizontally
Up to this point, some of the readers might bear a question: “why leave both components inside a single service when you could separate them?”
While microservices were a hot topic couple of years ago, nowadays more organizations start realizing that doing microservices correctly is hard. It requires certain engineering capabilities (distributed logging, failure recovery) as well organizational capabilities (code ownership separation, maintaining up-to-date contracts between services, robust deployment strategy). All this should serve as a precaution for those who use microservices solely as a tool to split their codebase into more manageable pieces. And this is why I’ve decided to stick with inter-process communication as the default architectural style.
Still, there might be cases when due to high load you have to scale the solution to endure even bigger loads. So the natural solution would be to handle file upload in parallel. However, parallelizing process on a single server instance has its own limits so eventually, you’ll come up with deploying service on multiple services (horizontal scaling). In such a case, the IO-intensive part that persists files to the database might benefit from horizontal scaling, while processor part may benefit from vertical scaling (say, adding more powerful processor to perform computation-intensive logic).
The ability to scale part of the system independently is one of the key reasons to use the microservices architectural style. (Another one is inverse Conway maneuver but it is beyond the scope of the article).
In such a case, both parts of the system are deployed independently and are communicating via message queue as on the figure below.
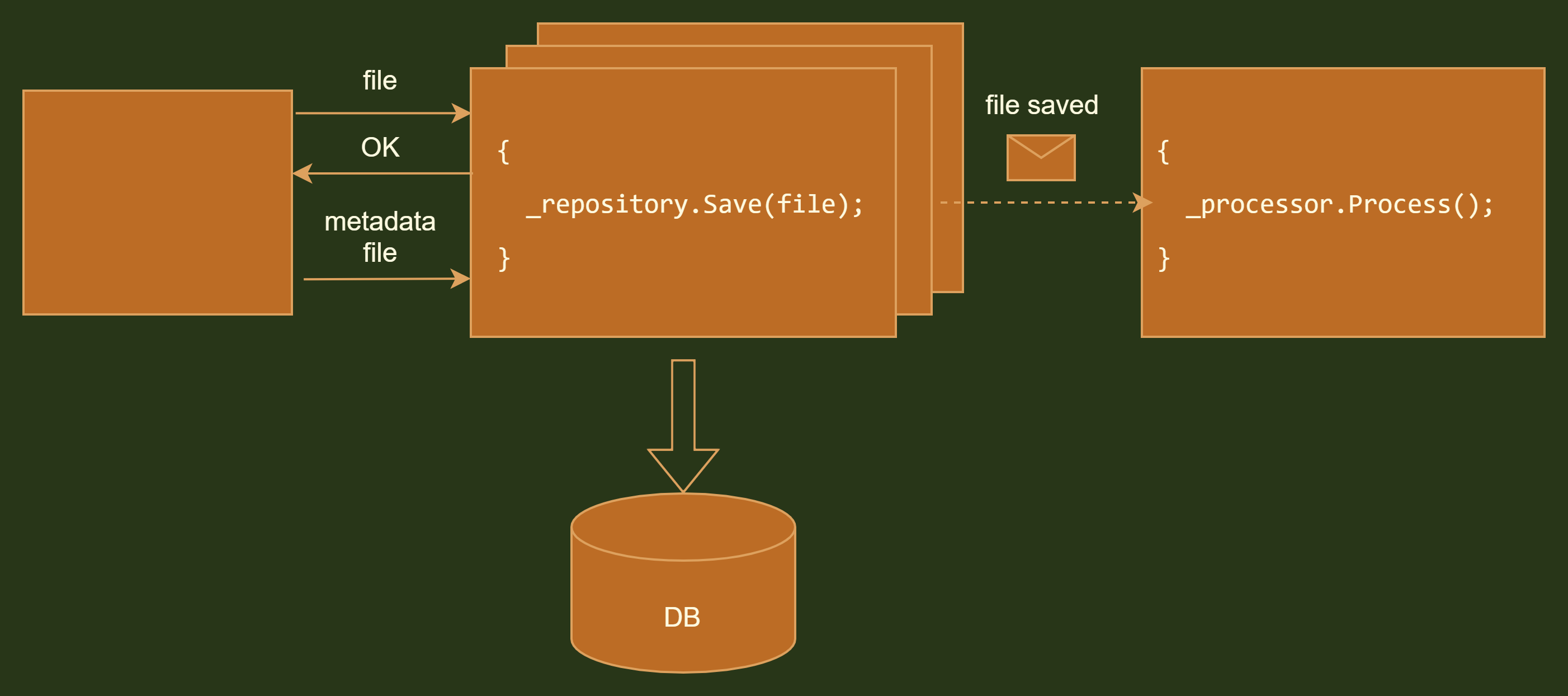
Reducing HTTP request duration
Another area of interest is customer-facing UI applications. Numerous studies reveal how an increase in page load time leads to customer dissatisfaction. Since HTTP call duration is an integral part of page load time naturally we want to reduce it too.
Let’s have a look at the following hypothetical code responsible for registering users in the application.
public async Task<IActionResult> FlushTemporary(CancellationToken token)
{
if (validator.IsValid(user))
{
await _repository.SaveUser(user, token);
await _mailingService.SendConfirmationEmail(user, token);
}
return Ok();
}
Needless to say that this leads to an extra wait for a customer during a registration step. Here again as in the example above we should extract confirmation email into the background job that will be executed after the registration step.
Conclusion
Synchronous communication introduces wait times that might be redundant during inter-system communication or in customer-facing applications. It’s crucial to understand which part of synchronous communication is unavoidable and which part might be done later. For the latter part, background processors are a neat trick to handle the issue.